Ruby on Rails (RoR) me sorprendió de entrada con características muy ventajosas que me hicieron preguntar por qué en ASP.NET o en PHP tengo que escribir hasta 10 veces más código para lograr lo mismo.
La respuesta no es “porque RoR es mejor”. El tema es que RoR está muy enfocado en una dirección, y es “el desarrollo de aplicaciones web basadas en bases de datos”. RoR también se maneja mucho con ciertas convenciones que de alguna forma nos limitan en esa dirección, pero nos permiten lograr resultados más rápido.
Un ejemplo de estas limitaciones es que RoR espera que cada una de las tablas de nuestra base de datos tenga un campo autonumérico definido como la primary key llamadoid. Si cumplimos con esa convención, RoR promete hacernos las cosas más fácil.
Por supuesto, RoR permite ciertos deslices de esas convenciones, pero pagando el costo de mayor cantidad de código.
Sinceramente no me puse a investigar qué pasa si queremos trabajar con modelos de datos un poco más complejos. Por ejemplo, si queremos modelar herencia en la base de datos, algo que suelo utilizar bastante. Otra cosa que noté es que las tablas de asociación de muchos-a-muchos no se modelan en RoR, es decir, no son representadas como objetos en el modelo; con esto, no sé qué pasaría si yo quiero agregar algún campo extra a estas tablas para calificar una asociación. Sinceramente son cosas que tengo que investigar.
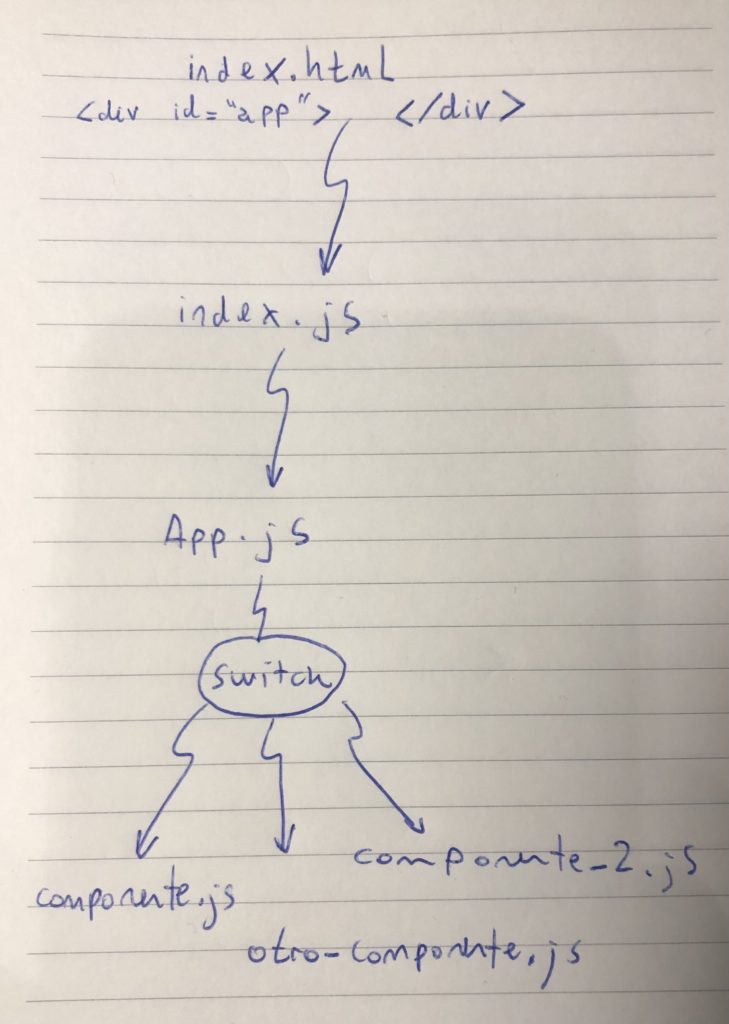
Patrón MVC
Ruby on Rails implementa el patrón MVC. Por alguna razón este patrón está de moda. Aunque, pensandolo bien, es un patrón que funciona MUY bien para aplicaciones web basadas en datos.
No voy a explicar el patrón MVC aquí, solo voy a explicarles cómo lo implementa RoR, ya que me costó un poquito entenderlo.
El Modelo (la M de MVC), en Ruby on Rails contiene clases que representan a las tablas de nuestra base de datos. Una característica destacable es que nosotros creamos estas clases pero no es necesario definir los atributos para acceder a los campos de las tablas que representan. Rails infiere esta información automáticamente a partir del nombre de la clase (para esto sirven las convenciones).
En las clases del Modelo podemos, además, agregar otra lógica propia de cada clase. Por ejemplo, si tenemos una clase Product, en principio, se vería así:
class Product < ActiveRecord::Base
end
Supongamos que queremos agregar código para calcular el precio con impuestos. En ese caso, la clase Product es el lugar indicado para hacerlo.
class Product < ActiveRecord::Base
def price_plus_taxes
price * 1.21
end
end
También podemos definir métodos estáticos:
class Product < ActiveRecord::Base
def price_plus_taxes
price * 1.21
end
def self.find_available_products
Product.find_by_available(1)
end
end
Una de las confusiones que tuve fue con el tema de los Controllers y las Views (C y V en MVC). Creí erróneamente que también debe existir un Controller por cada tabla y una carpeta dentro de View por cada tabla. Si bien es bastante común esto no tiene por qué ser así.
Los Controllers son clases que agrupan un conjunto lógico de páginas. Por ejemplo, páginas para listar y visualizar artículos. En ese caso tendríamos un Controller llamadoArticlesController con métodos list (para listar) y show (para visualizar). A su vez, tendríamos una carpeta articles con plantillas que llevarán los mismos nombres que los métodos: list y show.
Sin embargo, la forma en que manejamos las entidades de nuestro modelo en nuestros controllers es totalmente libre. Solo tenemos que tener en cuenta la relación que hay entre Controllers y Views, como mencioné arriba.
Características principales de Ruby on Rails
Hasta aquí hice una breve presentación de RoR y expliqué cómo está implementado el patrón MVC. Voy a hablar ahora de las características que más destaco de MVC, sobre todo porque me encantaría tenerlas en otros lenguajes.
En general, encuentro que las características que más me atraen de Rails son aquellas que facilitan el trabajo del programador. Creo que Rails sigue la misma filosofía de Ruby, de programar para seres humanos y no para máquinas. Las características de Rails están pensadas para el mundo real; se pensó en cuáles son las necesidades cotidianas más comunes de cualquier programador de aplicaciones web y se implementaron soluciones realmente inteligentes.
Mapeo automático
Al crear una clase de tipo Model, Rails automáticamente infiere las propiedades de la misma, mapeandolas a los campos de la tabla de la base de datos. Rails sabe a qué tabla corresponde cada clase del Model gracias a las convenciones de nombres.
Lo mejor de esto es que, al agregar un nuevo campo a una tabla, no hace falta tocar nada en el Model; la nueva propiedad estará disponible automáticamente.
Hasta el momento no se me ocurre si esto es posible de hacer con .NET. Tal vez se pueda utilizando un poco de Reflection, pero lo dudo; y si se puede, debe ser difícil. Claro, una diferencia fundamental entre Ruby y el CLR de .NET es que Ruby tiene un soporte nativo para meta programación y los lenguajes de .NET son compilados, lo que hace que esto sea un poco dificil.
Validación
Otro ejemplo de una solución inteligente. Mientras que en frameworks como ASP.NET o incluso en CakePHP (otro framework MVC, pero para PHP) las validaciones se realizan a nivel de interfaz de usuario, en Rails se definen las reglas de validación en el Modelo.
Validar que el nombre y precio de un producto no estén vacíos, y que el precio sea un número válido, es tan fácil como agregar esta línea al modelo:
class Product < ActiveRecord::Base
validates_presence_of :title, :price
validates_numericality_of :price
end
Automáticamente Rails va a impedir que guardemos datos que no cumplan con dichas validaciones, y nos va a mostrar los errores correspondientes.
ASP.NET ofrece los controles de validación. Pero configurarlos y usarlos no es tan simple. Además, debemos implementarlos cada vez que trabajemos con la entidad.
Funciones find
Leer registros de la base de datos para llenar objetos o colecciones es por lejos una de las tareas más comunes. Para facilitarnos esta tarea, Rails tiene muchas variantes de la función find. Por ejemplo, todas las clases del Modelo tienen una función find para traer todos los registros de su tipo. Por ejemplo:
Product->find(:all)
Devolverá un array con todos los objetos Product de la base de datos.
Product->find(:first)
Devolverá el primer objecto Product.
Esta función acepta también más argumentos para definir un poco mejor los resultados que queremos y cómo los queremos ordenados. Por ejemplo:
Person.find(:all, :conditions => [ "category IN (?)", categories], :limit => 50)
Traerá todas las Person que cumplan con la condición del segundo argumento.
Pero donde esto se pone realmente interesante es cuando llamamos a funciones como:
Product.findByPrice(9.99)
Para traer todos los productos cuyo precio sea 9.99.
Wine.findByType('Malbec')
Para traer todos los vinos cuyo tipo sea Malbec.
Todas las funciones findBy<campo> son automáticamente generadas por Rails en tiempo de ejecución, gracias a las características de meta-programación del lenguaje Ruby.
Esto nos puede ahorrar realmente muchísimo trabajo. ¡Piensen en la cantidad de veces que necesitaron recurrir a funciones de este tipo! Si bien en otros lenguajes podemos construir funciones del tipo findBy<campo>, para evitar la repetición del código, de todas formas tenemos que escribirlas al menos una vez. En Rails, ya están todas “escritas”.
Formularios
Otra de las características destacables de Rails es el manejo de formularios asociados a entidades del Modelo. Mediante el método form_for, creamos un formulario HTML que estará asociado a una entidad determinada:
<% form_for :person, @person, :url => { :action => "update" } do |f| %>
First name: <%= f.text_field :first_name %>
Last name : <%= f.text_field :last_name %>
Biography : <%= f.text_area :biography %>
Admin? : <%= f.check_box :admin %>
<% end %>
En el ejemplo, creamos un formulario para la entidad Person (esto lo definimos mediante el símbolo :person. La data se la pasamos en la variable @person. Y en el tercer argumento definimos qué acción ejecutar (en este caso, update).
Vean que luego utilizamos métodos especiales para crear los campos del formulario. Al utilizar los mismos nombres de los campos de nuestras tablas para los campos del formulario, Rails automáticamente sabrá cómo completarlos y sabrá luego cómo y dónde guardarlos cuando enviemos este formulario.
Sin dudas, esto simplifica muchísimo las cosas. Fíjense cómo controlamos este formulario desde la clase PeopleController:
@person = Person.findById(1);
¡Listo! No hizo falta ni siquera ir campo por campo asignando la propiedad correspondiente… form_for lo hace por nosotros.
Guardar
Lo bueno de guardar en Rails es que, cuando recibimos un form, recibimos también un array params, con todos los valores del formulario enviado. Entonces, con pasar este array params al método update o create, automáticamente Rails sabrá cómo guardar la entidad.
El método flash
El método flash puede parecer algo tonto, pero es muy útil. Su funcionalidad principal es pasar info entre peticiones diferentes. Uno de los principales usos es para mostrar notificaciones o mensajes de error.
Conclusión
Como ven, Ruby on Rails tiene muchísimas cosas interesantes. Cosas que tal vez no vamos a encontrar en otros frameworks y que se las vamos a envidiar.